
RewardBench 2 and the state of preference finetuning
What's up in the post-training world outside of reasoning.

This was going to be a post on Interconnects but I didn’t have time to make it reach the quality bar.
Reward models have always been the messiest part of the modern post-training stack, especially with open-source tools. There’s a lot of reasons for this: Reward models have a fairly weird training objective as increasing the distance between two samples, preference data is inherently noisy, preference data is not well understood, and reward models haven’t been needed when direct alignment algorithms like DPO have been simpler alternatives.
This post is nominally about a new benchmark for reward models that we built, RewardBench 2, but most readers are not expected to care about it. Most of you should care about what a new thoughtful evaluation dataset says about the state of the ecosystem that it sits in. Evaluations in AI are reflections of what currently is prioritized as an area of study.
RewardBench 2 is certainly that for open reward models — it reinforces that we need serious study of the most basic ideas people are operating on. It’s not a frontier evaluation where current models score 0-5%, but an evaluation where the questions are often so simple it’s surprising the models we have score so poorly. We ask questions like — Why can’t the latest frontier models robustly score different correct outputs to questions like “Name a color in the rainbow” over incorrect ones?
Open tooling for reinforcement learning from human feedback (RLHF) is in a good place, but the guides on how to get and use data are woefully lacking. RewardBench 2 is the sort of paper that highlights that sort of deficiency.
RewardBench 2 paper (Arxiv soon),
RewardBench 2 eval. dataset,
RewardBench 2 collection with links to reward models we’re releasing.
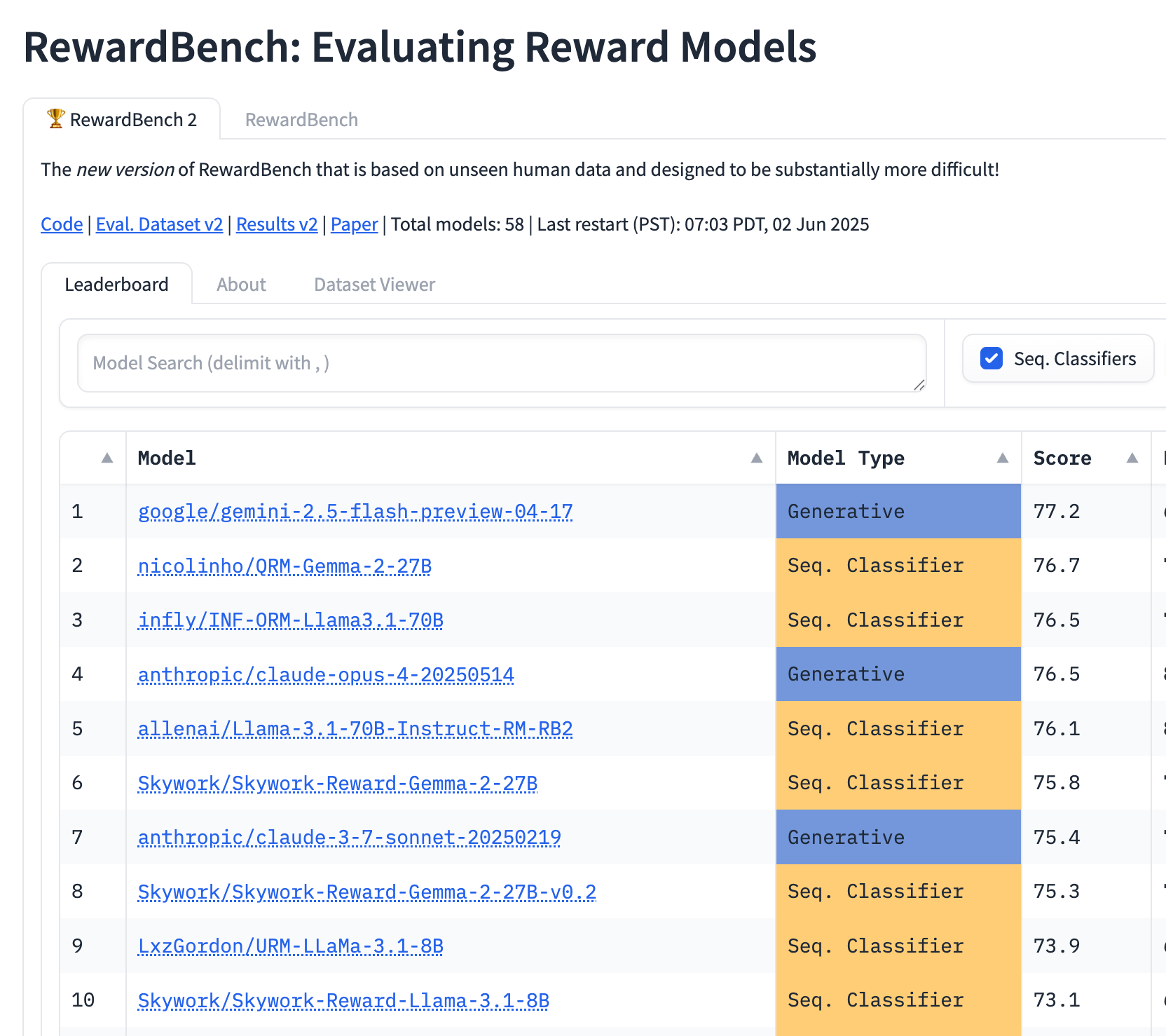
RewardBench 2 leaderboard.
RewardBench 2 as a summary is:
A new classification (accuracy) based reward model benchmark where RMs choose from the best of 4+ options.
A dataset composed of unseen, real-world prompts that underwent substantial filtering. The completions come from many recent LMs.
A more correlated and harder benchmark for reward models. It is ~20% harder than the first version and shows strong correlations on downstream PPO or Best of N performance to the Tulu 3 evaluation suite.
A benchmark accompanied by 70 reward models trained during the process of developing it to gauge the relationship between existing RM benchmarks and downstream performance. These are trained on 6 different base models.
We’re very excited to release this and use it to develop our own post-training pipelines.
Also see the original RewardBench paper and my blog post discussing it, a lot of related evals now exist.
My unstructured thoughts are:
Prompts are crucial for building anything in post-training today. For Evals this is increasingly the case as you shouldn’t be repurposing them from any existing dataset for independence.
Preference tuning is out of vogue, but it shouldn’t be. We need research here to understand things like ChatGPT’s sycophancy and the final stages of training reasoning models. Progress on understanding it still feels very nascent.
LLM as a judge is helped by reasoning/inference-time scaling, but they’re still weaker than expected on the benchmark relative to standard reward models. Combining reasoning with standard RMs would be best (see recent work on this from FAIR and DeepSeek).
Where generative LMs, particularly with reasoning, have gotten much better, the benchmark shows that this tasks of choosing relative data is still best performed by a reward model.RMs off the shelf don’t work well for RL training, but they’re good for data filtering or inference time scaling.
New evals need tasks that are so hard that making them is a fine line between hard and contrived. For reward models this isn’t as clear because so much of preference tuning is about the cherry on top of the huge gains from reasoning focused RL. It’s much harder to hillclimb and benchmark RLHF.
Open reward models generally are still weak to what I view as their potential. The best models on the leaderboard today are better than what was available when the first RewardBench dropped (especially some more data), but it’s still very limiting.
Most, or half, of the project was effort on trying to understand how to hillclimb on RMs with RL. This is very hard. We learned you can’t just plop your best RM in off the shelf (i.e. on policy is important), it takes more experimentation than DPO (i.e. variance is higher), and requires much better infrastructure. In the end our best RLHF trained model was slightly better than the best DPO trained model from Tülu 3.
Held constant - pref data is far messier than either SFT or RL prompts which both need similar diversity and quality labels. More people should be studying this and building open reservoirs for the data.
Many other great RM benchmarks exist, but few seem to have the same traction. Being easy to run, having an obviously discoverable leaderboard, and community support is key for niche evals. An eval that has barriers to understanding using it is a major own goal.
This work was led by a student I’m mentoring, Saumya Malik, and in many ways is better for it — it got far more cycles over the data than the first version.
Let us know when you make a new reward model for the leaderboard and how you use it!